
SIMPLE YSA IMPLEMENTATION WITH PYTHON
Thousands of data are recorded every second as a result of digitalizing lives with developing technology. This is a long list of data received from open or closed circuit cameras, log records of a server or data center, voice records of a GSM handset, and a huge pile of data that goes on and on because of data in a social media. With so much data in the digital field, it is almost impossible to analyze them with human power. This is because it is not a job that many people can do, even if they extract meaningful data from this large pile of data or use it to produce meaningful results. The solution to these problems is that the machines have their own ability to make decisions and make inferences. It is now an obligation of our age to extract the data that is meaningful in such data or to extract the data using it.
From this point on, artificial intelligence technique was developed, inspired by the study mentality of human intelligence, and is still continuing with serious studies. In this article we will use the artificial neural network(HSA) architecture which is one of the learning techniques of artificial intelligence. As you know, Python is a very wide range of languages, from Data Mining to scientific studies, artificial intelligence to cyber security. There are also very serious libraries on artificial neural networks. Some of them are coffe, theano, tensorflow, scikit, Panda and torch libraries.
Keras is an interface that uses the tensorflow or theano library in the background. We will make an application using tensorflow in the back with keras. Tensorflow is a serious library developed by Google and used in machine learning, some of which are made public in 2015.
Python Programming
However, we need to know how artificial neural network architecture works before we start writing our sample application, and we need to have some mastery of terminology on this subject. That’s why we’re going to talk a little bit. However, I would like to state that I wrote this article in order to remind you that you have some mastery of the subject and that I will write it.
The following illustration and Dec input layers(hidden layers) a three-layer structure including an artificial neural network model you can see.
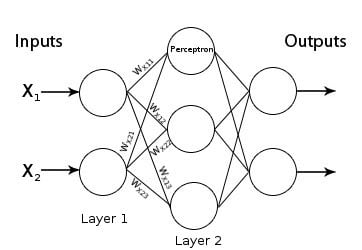
Each node you see above actually represents an artificial neural cell. And these are called perceptrons. Lines between perceptrons represent weights. The value of a perceptron will be a value after the value of all perceptrons in the previous layer multiplied by the corresponding weights and then the value of a perceptron will be a value after the value of an activation function after the total function has been passed. The result found is given as input to the next layer, and the picture below clearly explains what we mean. The following illustration shows the processes that are in each node you see above.
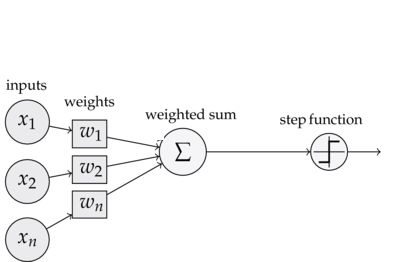
In the next picture, the xis represent our input values and the WIS represent our weights. In this paper, we will discuss the results of the experiment and the results of the experiment. And if this value is passed to the next layer, this cycle will continue until it reaches the output. This will be iterated for each value. And in each iteration, the weights will be rearranged to find a suitable result. This is called epoch. Because one of the most important factors affecting the results is our weight values. This is the simplest model of a network. Now, let’s take a look at how the data is processed in this model.;
We have a dataset. In this case, you must have a structure that has more than one entry but one output. For example, a user’s mouse movements, click counts, entered sites, such as the duration of these sites to take environmental variables, such as these values at the end of this person’s bot? Are you human? Let’s consider a dataset that stores its value.
10 thousand users as a result of the values of these people bot? Are you human? Suppose we have such a dataset that holds its value. These values are real values. So let’s imagine that they keep bot behaviors in any lab environment and that thousands of people are recording their activities on a computer. Because our model of ysa by making an inference of these examples showed him a sample of the bot of this? Are you human? He will find himself educating himself with these real values. But first of all, our system needs to complete the learning process.
We will give 9,000 of these 10 thousand data to our ysa model as educational data. Training data is the data provided to train an ansa model. In this example, the input and output values are the name given to the data. This is because the model will try to create a mathematical model between input values and output. When creating this model, variables such as weights, activation function, intermediate layers, perceptron numbers in layers are changed and the most appropriate value is attempted. And when our model reaches a threshold we set, learning ends. In this paper, we will discuss the relationship between the input and output of a neural network. We need to test after completing the system training. We will do the test with a thousand pieces of data that we have separated from 10 thousand pieces of data. However, the important thing here is that we give our test data only input variables. So that person is a bot? Are you human? We will not give the value that our model will find this value itself. And by comparing this value to actual value, we will calculate how many percent of our system is successful. For example, if a success of 90 percent and above is an acceptable value for us, then our model has been successful. No ysa model can give you a value with 100% certainty. There is always a margin of error and it has to be. Because the system itself produces a result from the given values. If 100 percent accurate answer is a system that did not learn ezber. This is called overfitting.
Also, if you notice that we use tables, which means that we will use matrices very heavily in Ysa. You will see that we will also use the numpy library when we have already implemented it. In fact, we understand what we are doing in the background and learning how to do what we call this event is performed very well simulating tensorflow’s web application certainly see. Play with the parameters, play with the parameters. ;)
For example, if you want to create a model, you need to create a model for the model.
First of all, we have to have a database to train our system. For this, there are major dataset repos. Look at these addresses.
A system must have enough data in its database for it to learn. If there is little data, the system will fall into memory.
The data in our database must be reasonable. Because the system is learning using that data.
Although the lack of missing and incorrect data does not affect the learning of the system very seriously, the system can not learn after a certain level.
Never use your training data as test data at the same time. Your results will not be healthy. Test with data that the system has never seen before.
SIMPLE YSA IMPLEMENTATION WITH PYTHON
After all these sentences, we have finished the story section and we are ready to move on to the technical section. The dataset we will use is about 800 people’s body, which means there are about 8 values. These include the number of pregnancy, plasma glucose concentration, diastolic blood pressure, skin thickness, insulin amount used, body mass index, diabetes family and age values. And the last column contains a value of 1 or 0. If you have Type 1 diabetes, your doctor may recommend a blood test to check for diabetes. Let me get a little braces out of here. Every data in our database must be numeric. Because mathematical operations are performed on these values. Even the outputs should be numeric, at least they should be expressed in that way.
If there are libraries that we will use first, we will use a virtual environment to isolate our application in other Python libraries so that it does not affect the libraries we use in other projects. Therefore;
$sudo pip3 install virtualenv
After installation is complete ;
$sudo virtualenv keras
by saying keras ‘ name to create an isolated environment;
source /bin/activate
let’s activate our isolated environment. Now, let’s load the libraries we need.
$sudo pip3 install numpy $sudo pip3 install tensorflow $sudo pip3 install keras
When the process is finished, everything is ready for us to implement. Now we can start writing our Python code. First, let’s import the packages we will use.
fromkeras.modelsimportSequentialfromkeras.layersimportDensefromtermcolorimportcprintimportnumpy
dataset = numpy.loadtxt(“pima-indians-diabetes.csv”, delimiter=”,”)
X=dataset[:600,0:8]Y=dataset[:600,8]
model = Sequential()
model.add(Dense(20, input_dim=8, init=’uniform’, activation=’relu’))
model.add(Dense(12, init=’uniform’, activation=’relu’))
model.add(Dense(8, init=’uniform’, activation=’sigmoid’))
model.add(Dense(1, init=’uniform’, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
Python Open Source Project
We’re running our model. The first parameter is the input, the second parameter is the output. 3. our parameter epoch value. In other words, the number of attempts to reorganize the weights until they find the closest value to the solution. Batch refers to the number of data to be retrieved at once. We wanted verbose not to show in case of any error.
model.fit(X, Y, nb_epoch=150, batch_size=10, verbose=2)
We calculate the percentage of success of our model.
scores = model.evaluate(X, Y)
And finally, we press the result of our model on the screen.
print(“%s: %.2f%%” % (model.metrics_names[1], scores[1]*100))
Yes, so far our model has found a model that is interreligious between input and output using the examples we gave and the training has ended. From now on, we will give our test data to the system and calculate how successful it is. Now we will give the 1000 values to our system, and we will compare the results of our model to the actual results and see how successful it is. Let’s continue by typing the following code again in the same Python file.
test_verisi=dataset[600:696,0:8]predictions=model.predict(test_verisi)
dogru=0yanlis=0toplam_veri=len(dataset[600:696,8])forx, yinzip(predictions, dataset[600:696,8]):x=int(numpy.round(x[0]))ifint(x)==y:cprint("Tahmin: "+str(x)+" — Gerçek Değer: "+str(int(y)),"white","on_green", attrs=['bold'])dogru+=1else:cprint("Tahmin: "+str(x)+" — Gerçek Değer: "+str(int(y)),"white","on_red", attrs=['bold'])yanlis+=1("n","-"*150,"nISTATISTIK:nToplam ", toplam_veri," Veri içersinde;nDoğru Bilme Sayısı: ", dogru,"nYanlış Bilme Sayısı: ",yanlis,"nBaşarı Yüzdesi: ",str(int(100*dogru/toplam_veri))+"%", sep="")